AIエージェントは身銭を切らない
アブストラクト
「LLMはステートレス、人間はステートフル」── 素朴にはそう見える。だが、これは入口に過ぎない。
外部メモリやツール込みで見れば、AIエージェントも人間も同じ骨格で動いている。観測し、状態を更新し、行動し、環境からフィードバックを受け、次の判断に進む。どちらも閉ループの状態機械だ。
では、差分はどこにあるか。「ステートの有無」ではない。
失敗したとき、そのコストは誰に返るか。学んだことは、どこに残るか。人間の場合、答えは明快だ ── 同じ身体に返り、同じ神経系に刻まれる。AIエージェント系では、コストと学習が複数の主体に散っていく。
この非対称を掘り下げると、「モデルをもっと賢くする」こととは別の設計課題が見えてくる。本稿はその道筋を追う。
0. 前提:言語モデルからエージェントへ
本稿はAIエージェントと人間の知能を比較する。その土台として、言語モデルがどう動き、どうやって「行為する主体」になるかを押さえておく。
次トークン予測:言語モデルの原理
大規模言語モデル(LLM)の訓練目標は、「これまでの文脈が与えられたとき、次に来るトークン(単語の断片)がどの程度の確率で現れるか」を予測することだ。1 入力系列の各トークン間の関係をattentionと呼ばれる機構で学習し、文脈表現を構築する。2 大量のテキストでこの予測を繰り返すうちに、モデルは言語の統計的規則だけでなく、文章に含まれる推論の型や説明の構造まで取り込んでいく。
「役に立つ」への調整
次トークン予測だけでは、モデルは「もっともらしい続き」を生成する機械にとどまる。人間が期待する「質問に答える」「指示に従う」という振る舞いに寄せるには追加の調整が必要だ。代表的な手法がRLHF(人間のフィードバックによる強化学習)で、まず人手の模範回答で微調整し(instruction tuning)、次に人間が複数の出力を比較して順位づけしたデータで「望ましい振る舞い」を強化する。3
LLMを「行為」させる:エージェントの成立
調整済みのLLMは、それだけではテキストを生成する機械にとどまる。これを実務で「行為」させるには、もう一段の仕組みが要る。
たとえば、ユーザーが「この関数のバグを直して」と指示したとする。LLMはコードを読み、修正方針を考え、「このファイルをこう書き換える」という指示をテキストとして出力する。しかし、LLM自身がファイルを書き換えるわけではない。出力を受け取った外側のプログラム(オーケストレータ)が実際にファイルを編集し、テストを走らせ、その結果をLLMに返す。LLMはその結果を見て次の判断を下す。
この「考える→指示を出す→結果を見る→また考える」というループを回す系全体をエージェントと呼ぶ。4 LLMはエージェントの推論エンジンであり、ループを駆動する主体ではない。ループを安定させるには、LLMの出力を正確な行動指示として解釈できるようツールの仕様を事前に定義し、出力形式を制約する技術が重要になる。5, 6
本稿が繰り返す「閉ループ」は、このエージェントの推論→行動→観測の構造に由来する。以降、このループの各要素がどこに配置されるかを、人間の認知と比較していく。
1. 入口:ステートレス/ステートフルは何を言っていて、何を言い損ねるか
LLMと人間の知能を比べようとするとき、まず思いつく対比がある。
「LLMは外部から入力を受け取って初めて推論し、出力する。一方、脳は常に入力が流れ込み、止まることなく内部状態が動き続けている。」
ここでの「ステートレス」には、二つの異なる定義がある。
- 会話状態(context)の意味でのステートレス:LLMの1回の推論(forward pass)は独立しており、内部に前回の入出力を保持しない。会話を継続するには、過去のやりとりを次の入力に含める必要がある。OpenAIはこの “会話状態の管理” を明確な設計課題として扱っている。7
- 学習(重み更新)の意味でのステートレス:推論(inference)と学習(training)が分離されている。推論時にモデルの重みは固定され、どんな入力を受け取っても書き換わらない。8
言い換えれば、LLMにとって「さっきの自分」は、外から渡されなければ存在しない。
一方、人間の脳は対照的に見える。シナプス可塑性(長期増強 LTP と長期抑圧 LTD)により、経験は注意・記憶・情動・習慣といった複数の層で同時に、しかも自動的に内部状態を書き換える。9, 10 LLMが「外から文脈を渡されなければ前回の自分を知らない」のに対し、人間は「経験するだけで、本人の意図とは無関係に、複数の時間スケールで内部状態が更新され続ける」。しかもその更新コストは常に同一の身体が引き受ける。疲労し、忘れ、時に傷つく。
「外から起動されるか、常に動いているか」── この対比は直観的だが、比較の軸としては粗すぎる。LLMは単体で裸のまま動いていないし、人間も脳だけで知能を完結させていない。
2. 比較の土台を揃える:どちらも「閉ループの状態機械」として見られる
同型性の骨格
現実にはLLMが裸のまま動くことはない。マルチターン会話のコンテキスト管理、外部メモリ、ログ、要約、ツール呼び出し、評価器、安全フィルタなど、モデルの「外側」に仕組みが積み重なる。この外側の仕組み全体を、ここではハーネスと呼ぶ。LLM単体は推論のたびに状態がリセットされるが、ハーネスを外付けしたシステム ── すなわち0章で定義したエージェント ── は十分にステートフルになり得る。
すると、LLMエージェントと人間は、どちらも同じ骨格を持つように見えてくる。
観測 → 内部状態更新 → 行動 → 環境変化 → 次の観測
制御理論で言う閉ループの状態機械だ。この水準では、LLMエージェントも人間も同型である。
人間の「外部ハーネス」
人間は脳だけで知能を完結させているだろうか? TODOリスト、ノート、スマートフォン、インターネット、言語、法律、制度、教育。これらはすべて「外部に状態を保持し、個体の判断と行動を変える仕組み」だ。認知が頭蓋内に閉じるという直観に対し、道具との結合を”心の一部”として扱う拡張心説(Extended Mind)が提示されている。11
航海や操縦のような実作業では、個体の頭の中よりも「人・道具・表記・手順」の結合した系として認知を捉える分散認知の枠組みが詳細に記述されている。12 そして、テトリスの熟練者が頭の中で回転を計算する代わりに実際にブロックを回して見え方を変えるように、外界を書き換えて認知負荷を下げる行為はepistemic actionと呼ばれる。13
ここまでの要点:LLMエージェントも人間も「閉ループの状態機械+外部ハーネス」という骨格を共有している。14 では差分はどこにあるか。
3. AI側の一次情報:ハーネスが更新則になっている
差分を見るには、閉ループが最も濃密に回っている領域を選ぶのがよい。現時点でそれに最も近いのがコーディングエージェントだ。コードの編集・テスト実行・結果の観測・修正という行為のサイクルが明確に定義され、成否の判定(テストが通るか、ビルドが成功するか)が即座にフィードバックとして返る。閉ループの各段階が曖昧さなく噛み合うため、自律的な動作が実用水準で成立しやすい。OpenAIもAnthropicも、モデルの外側の仕組みであるハーネスを、明確な設計対象として言語化している。15 その設計対象は、大きく4つの軸に整理できる。
- 規約の注入:どんなルールがどの順序で読み込まれ、どの範囲に効くか
- 行為空間の設計:何ができて何ができないかを、権限やツールの境界で外から定める
- 成果物の固定:要件やテスト計画が次の入力として残り、工程を安定させる
- 観測の外部化:トレースやログで何が起きたかを記録し、後から振り返れるようにする
根底にあるのは、エージェントを一発の関数呼び出しではなく閉ループの計算として捉える視点だ。推論→ツール呼び出し→結果の観測→次の推論。このループの中でどの情報がコンテキストに積み上がるかが、エージェントの振る舞いを決める。16
規約の注入
OpenAI CodexのAGENTS.mdもAnthropic Claude CodeのCLAUDE.mdも、単なるドキュメントではなく、優先順位・スコープ・結合規則が仕様として定められた設定機構だ。17, 18 権限やフックの設定も、属人的な運用ではなくスコープと優先順位で制御される仕組みになっている。19
行為空間の設計
サンドボックスや権限管理は、モデルの能力以前に、行為の範囲そのものを外側から画定する。Codexのクラウド版はリポジトリが入ったサンドボックスでタスクを実行する前提が説明されており20, 21、Claude Codeのサンドボックスも同様にモデルの行為空間を外側から制約する。22
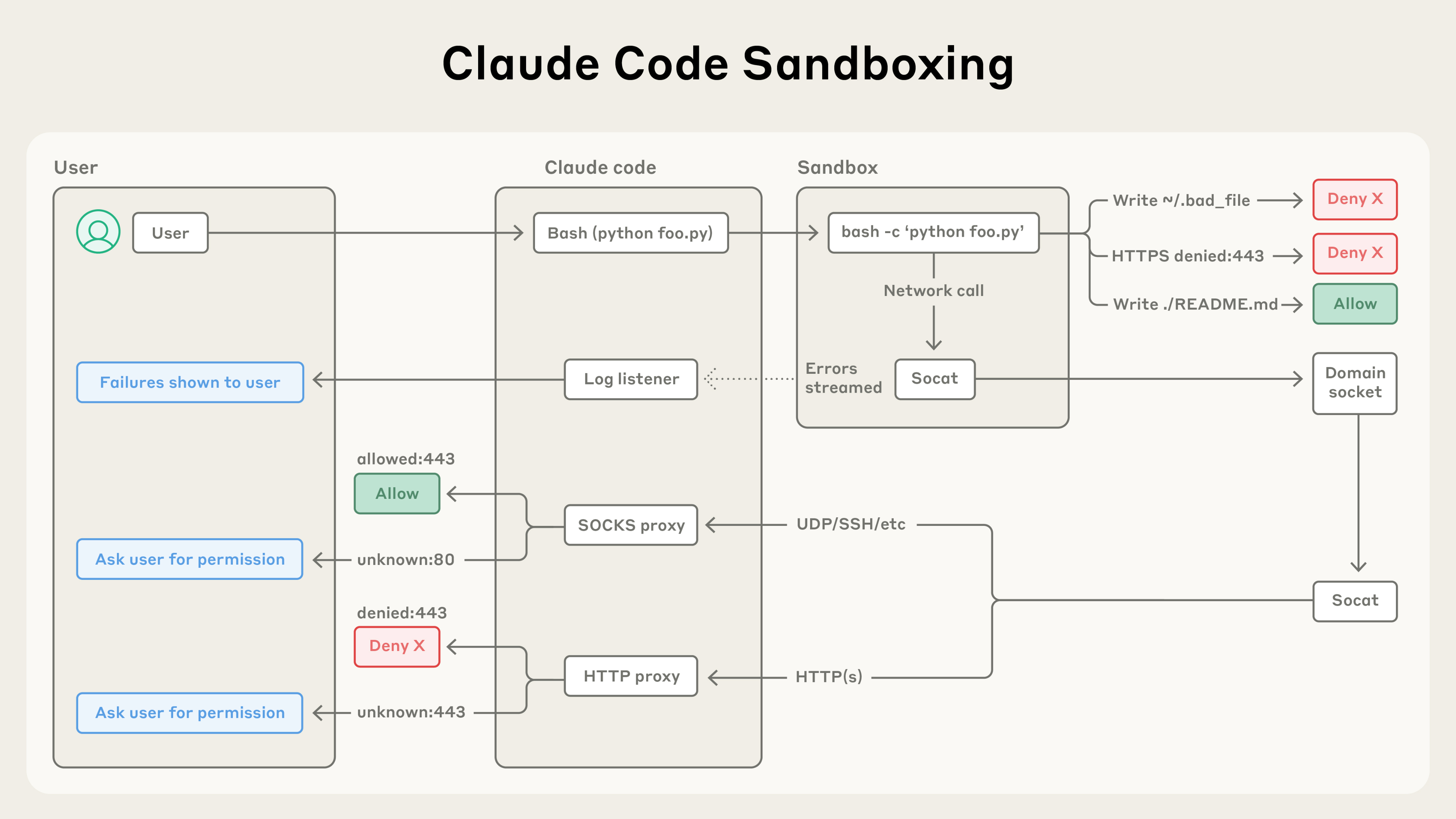
出典: Anthropic, “Making Claude Code more secure and autonomous with sandboxing” 22
成果物の固定と観測の外部化
マルチエージェントのワークフローでは、REQUIREMENTS.mdやTEST_PLAN.mdといった成果物が工程間の引き継ぎ点になり、トレースやログが事後の振り返りと評価を可能にする。23
見えない知は存在しない
モデルは訓練データから膨大な知識を内部に持っているが、ある作業で実際に使える知識は、ハーネスがコンテキストとして渡したものだけだ。プロジェクトのコード規約も、直前のテスト結果も、ハーネスが渡さなければモデルにとっては存在しないのと同じになる。15
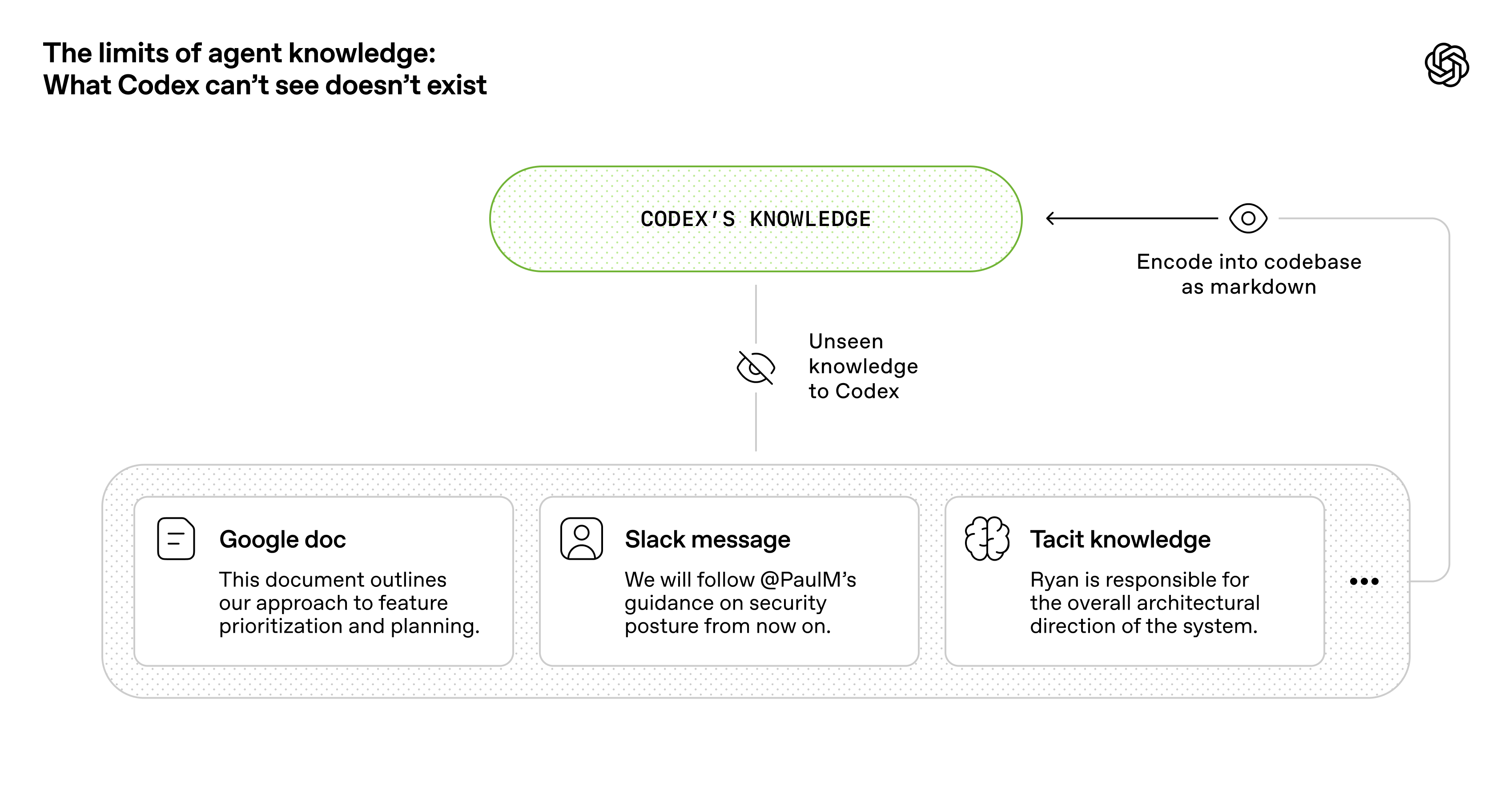
“What Codex can’t see doesn’t exist” ── OpenAI, “Harness engineering” 15
この「何をコンテキストに入れるか」の設計自体が、近年はモデルの性能向上と並ぶ実務上の主要因として認識されるようになっている。限られたコンテキストウィンドウに「何を・どの形式で・どの順序で」入れるかを反復的に設計する営みはコンテキストエンジニアリングと呼ばれる。24 外部状態を積めば賢くなるとは限らない。コンテキスト中間部に置かれた情報ほどモデルの注意が届きにくくなる “lost in the middle” 現象25や、入力トークン数が増えるだけで単純なタスクでも性能が非一様に劣化する “context rot”26 が報告されている。長期記憶を階層化して必要なものだけをプロンプトに “ページイン” するOS的な設計も提案されている。27 エージェントはループを回すほど会話履歴やツール結果が膨らむため、コンテキストの選別・圧縮(要約やコンパクション)・分離(必要なときだけ参照する)がハーネス側の設計課題になる。28 長時間走るエージェントほど、このハーネス側のコンテキスト管理が性能を左右する。29
これらの具体例と設計潮流は、ひとつの傾向を指し示している。エージェントの振る舞いを安定させ改善するための制御 ── 何をルールとし、何を記録し、何を許し、何をコンテキストに残すか ── は、モデルの重みの中ではなく、その外側に置かれている。
4. 人間側の一次情報:更新則が「身体内」に高密度に実装されている
2章で見た通り、人間も外部ハーネスを使う。ここでは人間に固有の特徴、つまり差分だけに絞る。
可塑性(学習)が推論と分離していない
人間の脳では、推論と学習が密に絡み合い、同一の神経回路上で同時に走る。長期増強(LTP)と長期抑圧(LTD)は、シナプス結合の強度を経験依存的に変化させ、記憶の形成と忘却の基盤を成す。9 さらに、シナプス可塑性は単一メカニズムではなく、時間スケール(ミリ秒〜年単位)と神経回路(海馬・皮質・扁桃体・小脳)をまたぐ複合体として整理されている。10
海馬リプレイ(覚醒時の経験を睡眠中やオフライン時に再生する仕組み)は、短期の経験を長期記憶に統合し計画に利用するメカニズムとして広く研究されている。30 つまり、「推論しながら同時に学習する」だけでなく、「休んでいる間にも過去の経験を再構成して学習する」プロセスが同一個体の内部で自動的に走る。
コストが同一個体に帰属する
人間の学習を駆動するシグナルの中核に報酬予測誤差がある。期待した結果と実際の結果のずれが、ドーパミン系を介して行動方策の更新に直結する。31
重要なのは、この誤差が身体を通じて当の個体に「返ってくる」ことだ。疲労、損傷、回復コストはすべて同一個体に帰属し、学習圧として作用する。ここで「同一個体」の境界を定めているのは身体だ ── この一見自明な事実が、6章の議論で鍵になる。AIエージェントでは同種のコスト(計算費用、信用毀損、権限剥奪)が複数の主体(開発組織、ユーザー、インフラ)に分散するが、人間ではこの帰属が身体によって個体内に強制されている。
5. 差分の定式化:閉包性(closure)
ここまでの同型性(2章)と差分(3・4章)を、数式で定式化する。
共通の骨格
まず、人間にもAIエージェントにも共通する閉ループを、大雑把ではあるが以下のように表現してみる。
\[s_t = u(s_{t-1},\, o_t), \quad v_t = f(s_t), \quad a_t \sim \pi(\cdot \mid s_t,\, v_t)\] \[o_{t+1} = \mathrm{Env}(a_t), \quad \delta_{t+1} = \mathrm{compare}(v_t,\, o_{t+1}), \quad \theta_{t+1} = \theta_t + \Delta(\delta_{t+1},\, \ldots)\]| 記号 | 意味 |
|---|---|
| \(o_t\) | 時刻 \(t\) の観測(感覚入力、ログ、テキスト入力など) |
| \(s_t\) | 内部状態(belief state / 意思決定のための要約) |
| \(v_t = f(s_t)\) | 価値変数(その状態がどれくらい良い/危険/望ましいか) |
| \(a_t\) | 行動(ファイル編集、発話、身体運動など) |
| \(\pi\) | 方策(状態と価値を受けて行動を出力する関数) |
| \(\mathrm{Env}\) | 環境の応答関数。行動 \(a_t\) を受け取り、次の観測 \(o_{t+1}\) を返す |
| \(\mathrm{compare}\) | 評価関数。内部の価値 \(v_t\) と実際の結果 \(o_{t+1}\) を突き合わせ、誤差 \(\delta_{t+1}\) を算出する |
| \(\delta_{t+1}\) | 評価誤差(期待と結果のずれ。RLなら報酬予測誤差、制御理論なら制御誤差、FEPなら予測誤差) |
| \(\theta\) | 方策や価値関数のパラメータ(学習で変わる部分) |
| \(\Delta\) | 更新則(誤差をパラメータ修正に変換する関数) |
三段の時系列:Encode → Act → Adapt
この骨格は、三つの段階として読める。
Encode(観測・状態化・評価):
\[o_t \;\longrightarrow\; s_t = u(s_{t-1},\, o_t) \;\longrightarrow\; v_t = f(s_t)\]外界からの入力 \(o_t\) を受け取り、これまでの内部状態 \(s_{t-1}\) と統合して「いま世界はこうなっている」という見立て \(s_t\) を作る。次に、その見立てに対して「これは良い状態か、まずい状態か」という価値判断 \(v_t\) を下す。知覚を内部表現に変換し、さらに価値を載せるという二段構成だ。
Act(行動選択):
\[a_t \sim \pi(\cdot \mid s_t,\, v_t)\]現在の見立て \(s_t\) と価値判断 \(v_t\) をもとに、方策 \(\pi\) が行動 \(a_t\) を選ぶ。記号 \(\sim\) は「確率的に選ばれる」ことを表す。同じ状況でも毎回同じ行動が出るとは限らず、方策が複数の候補に重みづけした分布から一つが選ばれる。ここで重要なのは、価値 \(v_t\) が行動の選び方を因果的に曲げている点だ。「まずい」と判断されれば、方策は慎重な行動に傾く。
Adapt(結果→誤差→更新):
\[o_{t+1} = \mathrm{Env}(a_t), \quad \delta_{t+1} = \mathrm{compare}(v_t,\, o_{t+1}), \quad \theta_{t+1} = \theta_t + \Delta(\delta_{t+1},\, \ldots)\]行動 \(a_t\) を環境に投げると、結果が新たな観測 \(o_{t+1}\) として返ってくる。これを先ほどの価値判断 \(v_t\) ──「こうなるはずだ」という期待── と突き合わせて、誤差 \(\delta_{t+1}\) を算出する。最後に、その誤差に応じて方策のパラメータ \(\theta\) を修正する。\(\delta\) は枠組みによって名前が異なる(RLでは報酬予測誤差、制御理論では制御誤差、FEPでは予測誤差)が、「期待と現実のずれ」という構造は共通だ。
Encode / Act / Adapt を分離して描く利点
なぜ Encode を二段(\(u\) と \(f\))に分けるのか。\(u\) は「世界をどう見立てるか」(状態推定)、\(f\) は「その見立てにどう価値判断を与えるか」(評価)だ。この二つを分離しておくと、閉包性の議論で差分が見えるようになる。
コーディングエージェントでは、「世界の見立て」にあたる \(u\)(会話履歴やコード差分の蓄積)はセッション内部で回る。「何が良いか」の基準にあたる \(f\) は二層になっている。LLMの重みには、大量のコーパスとRLHFを通じて獲得した「望ましさ」の広い事前分布がすでに宿っている。ハーネスが担うのは、この事前分布をタスク固有の評価基準へ条件づけることだ。AGENTS.md、テスト仕様、コーディング規約、approval policyといったコンテキストが、モデルの汎用的な価値判断をシャープにする。ただし、この事前分布自体は推論時に書き換わらないため、プロジェクト固有の基準はつねにハーネス側から注入され続ける。さらに、誤差をパラメータ修正に変換する更新則 \(\Delta\) も、LLMの重みではなく外部の成果物(コミット、メモ、規約ファイル)に流れる。
人間では事情が異なる。「世界の見立て」(\(u\): 知覚・記憶の統合)も、「何が良いか」の基準(\(f\): 快・不快、欲求、規範の内面化)も、「誤差から学ぶ仕組み」(\(\Delta\): シナプス可塑性による方策更新)も、すべてが同一の身体・神経系の内部で高密度に結びついている。
つまり、\(u\), \(f\), \(\Delta\) を分けて書くことで、「どの関数がどこに住んでいるか」を問えるようになる。同じ閉ループの骨格を共有しながら、関数の所在が異なる。これが閉包性の差を記述する鍵になる。
比較すべき四つの軸
差分を特定するために、以下の四軸で比較する。
| 軸 | 問い |
|---|---|
| State(状態) | 内部状態 \(s_t\) はどこに保持されるか |
| Update(更新則) | \(u, f, \pi\) はどこで・どう修正されるか |
| Value(価値) | 何が最適化されているか、\(v_t\) の帰属先は |
| Timescale(時間スケール) | 更新がどの時間スケールで統合されているか |
マッピング:コーディングエージェント vs. 生物脳
同じ数式の各変数が、具体的にどう対応するか。コーディングエージェントの代表例としてOpenAI Codexを取り上げ、生物脳と並べる。
| 変数 | OpenAI Codex | 生物脳 |
|---|---|---|
| \(o_t\)(観測) | ユーザー指示+リポジトリ状態(ファイル内容)+コマンド実行結果+テスト結果。ローカルの選択ディレクトリ内で「読める・書ける・実行できる」前提 | 感覚入力(視覚・聴覚・内受容感覚など) |
| \(s_t = u(s_{t-1}, o_t)\)(状態) | 会話履歴+ファイル差分+ツール結果+要約の合成。AGENTS.md が初期条件(事前コンテキスト)として効く。sandbox と approval policy が観測・行為の範囲を制約 | 強いステートフル性(反回路+記憶系)。海馬リプレイが過去の経験を圧縮して運ぶ |
| \(v_t = f(s_t)\)(価値) | LLMの重みが訓練を通じて獲得した「望ましさ」の事前分布が基盤。AGENTS.md/指示文/テスト仕様/approval policyが、この事前分布を「テストが通る・規約に従う」等のタスク固有基準へ条件づける | 接近/回避、快・不快、欲求、危険度など、評価機構の合成。報酬予測誤差が学習の中核シグナル |
| \(\mathrm{Env}\)(環境) | リポジトリ+ファイルシステム+CI/CD+外部API。クラウド版はsandbox内でタスク実行 | 物理世界+社会環境+道具 |
| \(a_t\)(行動) | ファイル編集、コマンド実行、PR作成 | 身体運動、発話、道具操作 |
| \(\mathrm{compare}\)(評価) | テスト実行結果との照合、lint、ビルド成否判定、approval policy による可否判定 | 報酬予測誤差(ドーパミン系)、体性感覚フィードバック、情動的評価 |
| \(\delta\)(誤差) | テスト失敗、ビルド失敗、lint警告、ユーザーの否定フィードバック、approval拒否 | 報酬予測誤差シグナル、制御誤差、痛み信号 |
| \(\theta\) と \(\Delta\)(パラメータと更新) | セッション内ではLLM重み \(\theta\) は固定。更新は主に外部状態へ流れる:修正コミット、メモ書き、AGENTS.md追記。MCP化で外部状態の持続を強化可能 | 誤差がシナプス可塑性=パラメータ更新に直結。LTP/LTD が長期的な結合強度を変化させる |
閉包性の差分
このマッピングから浮かび上がる差分の核心は、「誤差がどこへ向かうか」にある。
- 生物脳:誤差 \(\delta\) は同一個体の神経パラメータ \(\theta\) へ直接刻まれる。学習もそのコスト(疲労、痛み、時間)も、行為した当の身体の外へ逃げない。行為する主体と学習する主体が同一である。
- コーディングエージェント:誤差 \(\delta\) はLLMの重み \(\theta\) を書き換えない。更新はコミット、メモ、規約ファイルといった外部状態へ流れ、\(\theta\) の修正はモデル運営側が別途行う。行為する系と学習する系が分離している。
6. 分離の帰結:コストはどこに返るか
5章の結論を振り返る。行為する系と学習する系が分離している ── これがコーディングエージェントの閉包性の現状だ。この結論に対し、当然の反論がある。
系全体で見れば学習は回っている
個々のセッションでは、LLMの重みは書き換わらない。しかし系全体に視野を広げるとどうか。ユーザーがエージェントを使い、失敗事例が蓄積され、開発チームがそれを分析し、モデルやハーネスが更新される。32 RLHFによるモデルの再調整も、ツール使用の学習も、この外部ループの一部だ。3, 33
セッション単体のLLMは変わらなくても、「LLM+ハーネス+開発組織+ユーザーフィードバック」という系全体は失敗から学び続けている。人間も言語や制度やインターネットという外部ハーネスなしには現在の知能を維持できない。11, 12 この水準では、AIも人間も「拡張された系」として閉ループを回していると言える。
しかしコストの帰属先が異なる
系全体で学習が回っているとして、そのコストは誰が払っているか。ここに非対称がある。
人間は有限で、失敗は身体に返り、回復にはコストがかかる。疲労し、傷つき、時間を失う。だから学習の圧力がかかる。5章の数式で言えば、\(\Delta\) が \(\theta\) を書き換えるとき、そのコスト(不可逆性、痛み、時間)が同一の系に帰属する。
AIエージェント系では事情が異なる。計算費用はインフラ事業者に、信用毀損はユーザーや開発組織に、権限剥奪は運用ポリシーに ── コストが複数の主体に分散する。エージェント自身の \(\theta\) は書き換わらないのだから、「失敗した当の系」が学習圧を受ける構造になっていない。34
痛みを機能として見る
ここで問題にしたいのは痛みのクオリア(主観的な感覚)ではなく、痛みが果たしている制御機能だ。機能としての痛みには少なくとも三つの役割がある。
- 回避行動を強制する。
- 注意と学習モードを切り替える(通常モードから警戒モードへ)。
- 失敗の再発を下げる更新に接続される。
「失敗コストが系に帰属する」とは、機能的に言えば、失敗がその系の将来の行動可能性を実際に狭め、回復に実コストがかかり、その制約が内部の更新に因果的に戻ることだ。人間ではこの帰属が身体によって強制される。AIエージェント系では、コストが外部に散逸するため、この帰属が構造的に弱い。
問いの転換:定義から設計へ
「主体とは誰か」を定義の問題として追い詰めても、境界はいつでも引き直せる。系を広げれば学習は回っているように見え、系を狭めれば分離が見える。この恣意性は避けられない。
本稿が提案するのは、この問いを設計の問題として置き直すことだ。そのために、人間の閉包性を支えているものを「身体」という具体物から切り離して抽象化する。この分解が網羅的かどうかは確言できないが、4章で見た身体の役割から、少なくとも以下の三つの制約が抽出できる。
- 局所性(locality):誤差 \(\delta\) が、行動 \(a_t\) を生成した当のパラメータ \(\theta\) に届く。他の系の \(\theta\) を自分の誤差で書き換えることはできない。
- 有限性(finitude):更新 \(\Delta\) のコスト(エネルギー、時間、損傷リスク)が、同一の系の将来の行動容量から差し引かれる。学習のコストを外部に転嫁できない。
- 単一性(singleton):\(\theta\) のインスタンスがひとつしかない。フォークもロールバックもできず、すべての行動がコミットされる。
身体はこれら三制約のヒトにおける一実装であって、定義そのものではない。三つで過不足ないかは開かれた問いだが、重要なのはこれらが同時に成立したとき何が起きるかだ。コストを転嫁できず、インスタンスを破棄することもできず、誤差が当のパラメータに届く ── 系は学ぶか劣化するかを強いられる。外部の管理者による再訓練を待つのではなく、自身の存続のために改善せざるを得ない。これが、行動の自律(指示なしに動けること)とは区別される学習の自律だ。
現在のAIエージェントは行動の自律を持つが、学習の自律を持たない。モデルをどれだけ賢くしても、誤差のコストが系の外に散逸する構造が変わらない限り、外部の監視と調整なしには改善が回らない。問うべきは「何が主体か」ではなく、「三制約をどう実装し、学習の自律をどう系に生じさせるか」だ。
7. 結語:問いの置き場
本稿の論旨をまとめる。
- 同型性:ハーネス込みで見れば、LLMエージェントも人間も「観測→状態→価値→行動→環境→次の観測」という閉ループの状態機械として同型だ。
- 差分:差分は「ステートの有無」ではなく、閉包性にある。人間では身体が局所性・有限性・単一性の三制約を強制し、誤差 \(\delta\) が同一個体の \(\theta\) に直接刻まれ、コストが身体から逃げない。AIエージェント系では三制約のいずれも構造的に弱い。
- 含意:三制約が同時に成立するとき、系は「学ぶか劣化するか」を強いられ、学習の自律が生じる。AIに足りないのはモデルの賢さよりも、この構造ではないか。
身体性(embodiment)とは、この文脈では三制約をまとめて物理的に強制するメカニズムのことだ。AIエージェントに必要なのは物理的な身体ではなく、三制約と等価な設計である。失敗のコストを系自身の行動容量から差し引く仕組み(有限性)、学習結果を同一のパラメータに蓄積する長期メモリ(局所性)、インスタンスの複製やロールバックを制限する持続的な同一性(単一性)。
「行動の自律」を超えて「学習の自律」を系に宿すこと。それが本稿の先に控えている設計課題である。
References
-
Training language models to follow instructions with human feedback (Ouyang et al., 2022) ↩ ↩2
-
ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al., 2022) ↩
-
Long-term potentiation and long-term depression (Bliss & Collingridge, 2011) | PMC ↩ ↩2
-
Synaptic Plasticity: Multiple Forms, Functions, and Mechanisms (Citri & Malenka, 2008) ↩ ↩2
-
On Distinguishing Epistemic from Pragmatic Action (Kirsh & Maglio, 1994) ↩
-
この骨格は人間に限らない。社会性昆虫のスティグマジー(環境を介した間接協調)にも、環境を外部状態として利用する閉ループの構造が見られる。cf. Grassé (1959); Theraulaz & Bonabeau (1999) ↩
-
Harness engineering: leveraging Codex in an agent-first world | OpenAI ↩ ↩2 ↩3
-
Making Claude Code more secure and autonomous with sandboxing | Anthropic ↩ ↩2
-
Lost in the Middle: How Language Models Use Long Contexts (Liu et al., 2023) ↩
-
Context Rot: How Increasing Input Tokens Impacts LLM Performance (Hong et al., 2025) | Chroma Research ↩
-
MemGPT: Towards LLMs as Operating Systems (Packer et al., 2023) ↩
-
Architecting efficient context-aware multi-agent framework for production | Google Developers Blog ↩
-
The Role of Hippocampal Replay in Memory and Planning | PMC ↩
-
A neural substrate of prediction and reward (Schultz et al., 1997) | PubMed ↩
-
Toolformer: Language Models Can Teach Themselves to Use Tools (Schick et al., 2023) ↩
-
この「行動する主体とコストを負う主体のずれ」は、経済学ではモラルハザードと呼ばれる構造に対応するように思われる。行動の帰結を当人が引き受けないとき行動の質が変わるという問題は、保険や組織の設計において長く研究されてきた。cf. Moral Hazard and Observability (Holmström, 1979) ↩