Spike Sorting
Contents
2. Spike Sorting#
HD-MEAの各電極で観測される信号には,複数の細胞からの信号が混在している.また,Spike Detectionでみたように,単一の神経細胞の信号が複数の電極にまたがって観測される.単一の神経細胞の発火時刻に関する情報を得るには,複数細胞の活動電位が混在した信号を,統計処理により個々の細胞の信号に分離する操作が必要である.これをspike sortingと呼ぶ.
以下の画像は,HD-MEA上に培養された神経細胞を,神経突起のマーカーであるMAP2により免疫染色し,電気活動と重ね合わせた図である.[MullerBL+15]より引用した.

図上には神経細胞が3つ存在する.電極3を例にとると,3つの神経細胞の信号が混在しているものの,各神経細胞の空間的な分布が異なるために,spike波形の形状や振幅が異なることがわかる.神経細胞により各電極で観測されるspike波形の形状が異なるという前提に立ち,spike波形を統計的にクラスタリングすることにより,各細胞(unitと呼ばれる)の信号を推定することが可能である.
import h5py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import butter, filtfilt, find_peaks
from scipy import stats
from mpl_toolkits.axes_grid1.anchored_artists import AnchoredSizeBar
plt.rcParams['font.size'] = 12
plt.rcParams['figure.dpi'] = 200
def butter_bandpass(lowcut, highcut, fs, order):
nyq = 0.5 * fs
low = lowcut / nyq
high = highcut / nyq
b, a = butter(order, [low, high], btype='band')
return b, a
def bandpass_filter(sig, lowcut, highcut, fs, order=3):
if sig.ndim == 1:
sig = np.atleast_2d(sig)
sig = (sig - np.mean(sig, axis=1).reshape(-1, 1)) # offset with average
b, a = butter_bandpass(lowcut, highcut, fs, order)
return filtfilt(b, a, sig) # zero-phase filter
def peak_detection(sig, thr, distance=50):
peaks, _ = find_peaks(-1 * sig, height=thr, distance=distance)
return peaks
def thr_mad(sig, n=7):
return stats.median_abs_deviation(sig) * n
datadir = '../datasets/04/'
fs = 20000
# read signal
with h5py.File(datadir + 'data.raw.h5', 'r') as f:
sig = f['sig'][()]
mapping = f['mapping'][()]
# read electrode mapping
df_map = pd.DataFrame(mapping)
n_channels, n_frames = sig.shape
# filter signal
sig = bandpass_filter(sig, lowcut=300, highcut=5000, fs=fs)
amps = np.max(sig, axis=1) - np.min(sig, axis=1) # amplitude range for each channel
2.1. Waveform Extraction#
まず,単一の電極についてピーク検出し,spikeの波形を抽出する.ピーク時刻(spike時刻)を\(t_s\) [ms]とし,次の区間で信号の波形を取り出す.
本ノートでは,\(t_{pre}=1, t_{post}=2\) [ms]とする. サンプリング周波数\(f_s=20 \mathrm{kHz}\)とすると,抽出される信号の次元は\((t_{pre} + t_{post}) \cdot f_s\)である.
def extract_waveforms(sig, peaks, n_pre=20, n_post=40):
sig = np.atleast_2d(sig)
n_channels, n_frames = sig.shape
peaks = np.sort(peaks)
peaks_ = peaks[(n_pre <= peaks) & (peaks <= n_frames - n_post)] # waveforms must be within data range
waveforms = np.array([sig[:, peak - n_pre: peak + n_post] for peak in peaks_])
return peaks_, waveforms
def concat_waveforms(waveforms):
waveforms = np.atleast_3d(waveforms)
n_peaks, n_channels, n_frames = waveforms.shape
return waveforms.reshape(-1, n_channels * n_frames)
最大振幅をもつ電極でspike検出し,spike周辺の波形を抽出する.
# spike detection at the channel with maximum amplitude range
s = sig[np.argmax(amps)]
peaks = peak_detection(sig=s, thr=thr_mad(s), distance=50)
t_pre, t_post = 1, 2 # ms
n_pre, n_post = int(t_pre * fs / 1000), int(t_post * fs / 1000)
t = np.arange(-t_pre, t_post, 1000 / fs)
peaks, waveforms = extract_waveforms(s, peaks, n_pre, n_post)
waveforms = concat_waveforms(waveforms)
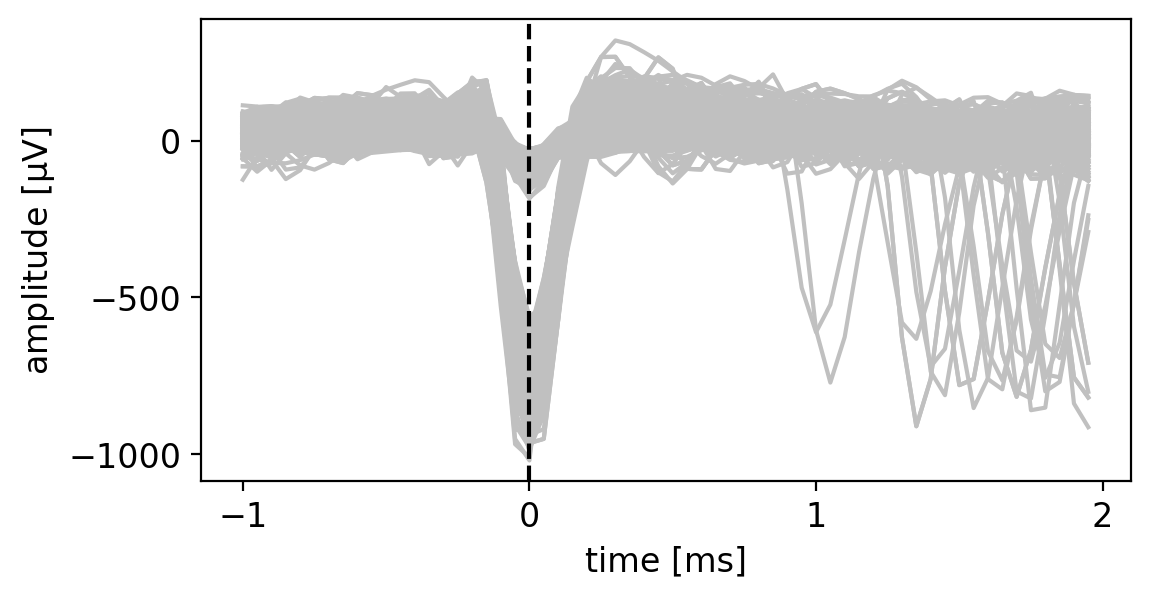
抽出された波形をプロットすると次のようになる.振幅の異なるさまざまなspike波形が混在することがわかる.また,\(t=0\)だけではなく,\(t>1\)の領域において別のspikeが重なった波形が存在することがわかる.
# randomly sample n_samples waveforms
rng = np.random.default_rng(0)
n_samples = 1000
plt.figure(figsize=(6, 3))
for waveform in rng.choice(waveforms, n_samples):
plt.plot(t, waveform, c='#C0C0C0')
plt.xlabel('time [ms]')
plt.ylabel('amplitude [$\mathrm{\mu V}$]')
plt.axvline(x=0, ymin=0.0, ymax=1.0, linestyle='dashed', c='k')
plt.locator_params(axis='both', nbins=4)
plt.show()
2.2. Feature Extraction#
次のステップでは,抽出された波形(snippetsと呼ぶ)について,何らかの特徴量を抽出し,クラスタを推定する.
解釈性の高い特徴量としては,振幅(amplitude)やpeak-to-valley widthなどが挙げられる.一方で特徴抽出を統計的に行う場合,PCA(主成分分析)やt-SNE, UMAP等の次元圧縮手法を用いる.本ノートではPCAを例にした解析を述べる.
from sklearn.decomposition import PCA
from sklearn.cluster import DBSCAN, KMeans
from sklearn.mixture import GaussianMixture
pca = PCA(n_components=2, random_state=0)
pca.fit(waveforms.T)
waveforms_pca = pca.components_.T
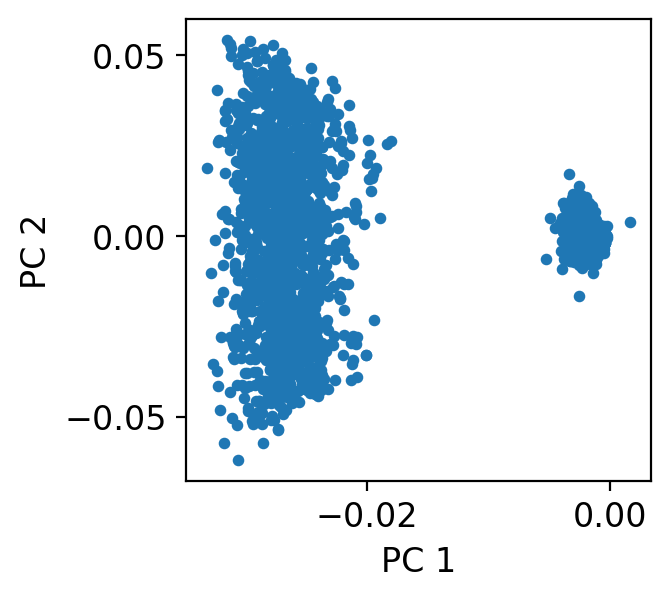
抽出された\((t_{pre} + t_{post}) \cdot f_s = 60\)次元の各波形を,PCAにより2次元に圧縮した結果が次の通りである.今回の例を肉眼で観察した場合,2クラスタが最適であると考えられる.
plt.figure(figsize=(3, 3))
plt.scatter(waveforms_pca[:, 0], waveforms_pca[:, 1], s=10)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.locator_params(axis='both', nbins=2)
plt.show()
PCAの結果に基づき,以下で3種類のクラスタリング手法 —— k-means,GMM(Gaussian Mixture Model; 混合ガウスモデル),DBSCAN(density-based clustering; 密度ベースクラスタリング)を試行し,クラスタリング結果を比較する.
def plot_clusters(ax, waveforms, labels):
for i in set(labels):
idx = (labels == i)
ax.scatter(x=waveforms[:, 0][idx], y=waveforms[:, 1][idx], s=10, label=f'unit {i}')
fig, axes = plt.subplots(1, 3, figsize=(9, 3))
n_clusters = 2
km = KMeans(n_clusters=n_clusters, random_state=0, n_init=10).fit(waveforms_pca)
plot_clusters(ax=axes[0], waveforms=waveforms_pca, labels=km.labels_)
gm = GaussianMixture(n_components=n_clusters, random_state=0).fit(waveforms_pca)
plot_clusters(ax=axes[1], waveforms=waveforms_pca, labels=gm.predict(waveforms_pca))
dc = DBSCAN(eps=0.01, min_samples=10).fit(waveforms_pca)
plot_clusters(ax=axes[2], waveforms=waveforms_pca, labels=dc.labels_)
titles = ['k-means', 'Gaussian Mixture', 'DBSCAN']
for ax, title in zip(axes, titles):
ax.set_xticks([])
ax.set_yticks([])
ax.set_title(title)
axes[1].legend(bbox_to_anchor=(0.5, -0.30), loc='lower center', borderaxespad=1, fontsize=12, ncols=2)
plt.show()
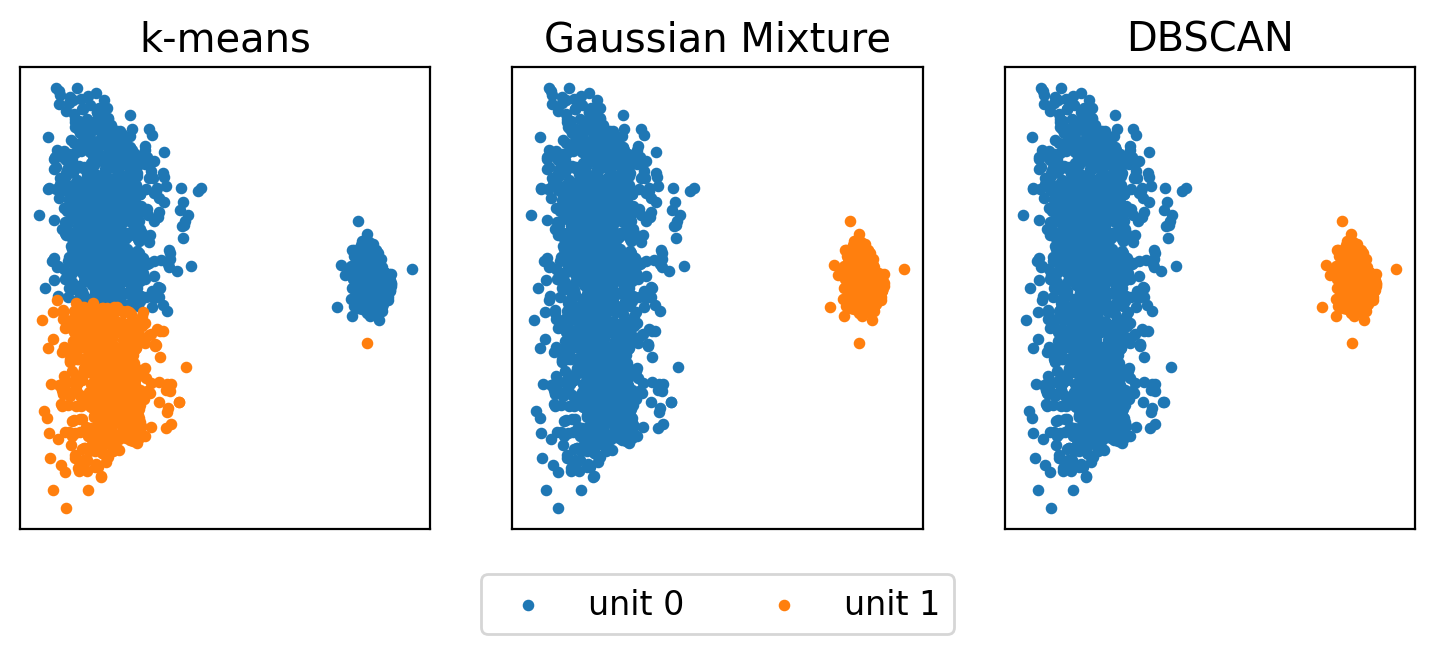
k-meansは各クラスタの分散が異なるケースに不向きであるため,左のクラスタがうまく分離できていない.一方で,GMMとDBSCANの結果は,今回のケースでは人間の直感と一致する(ただしパラメタのチューニングが適切になされているという前提がある).
その他のクラスタリング手法を含めた各手法の比較や特徴については,scikit-learnのウェブサイトが参考になる.
https://scikit-learn.org/stable/modules/clustering.html
spike-sortingを自動化する場合,クラスタ数などのパラメタをどのように決定するかという課題がある.k-means, GMMではクラスタ数を自動で決める必要があり,情報量基準やエルボー法といったプラクティスがある.k-meansの場合,BICを用いて拡張された手法であるx-meansを用いるという手もある.
DBSCANは,eps, min_samplesの二つのパラメタを決めれば,クラスタ数が自動で決定される上,外れ値を除去できるという性質を持つ.本ノートではDBSCANを例に解析を進める.
# clustering
dc = DBSCAN(eps=0.01, min_samples=10).fit(waveforms_pca)
labels = dc.labels_
n_clusters = np.max(labels) + 1
# plotting for each unit
fig, axes = plt.subplots(1, n_clusters, figsize=(4 * n_clusters, 3))
for i in range(n_clusters):
ax = axes[i]
ax.set_title(f'unit {i}')
idx = (labels == i)
# plot each waveform
for waveform in waveforms[idx]:
ax.plot(t, waveform, c='#C0C0C0')
# plot averaged waveform
ax.plot(t, np.mean(waveforms[idx], axis=0), linewidth=2.0, c=f'C{i}')
axes[0].set_xlabel('time [ms]')
axes[1].set_xlabel('time [ms]')
axes[0].set_ylabel('amplitude [$\mathrm{\mu V}$]')
plt.subplots_adjust(wspace=0.30)
plt.locator_params(axis='both', nbins=4)
plt.show()
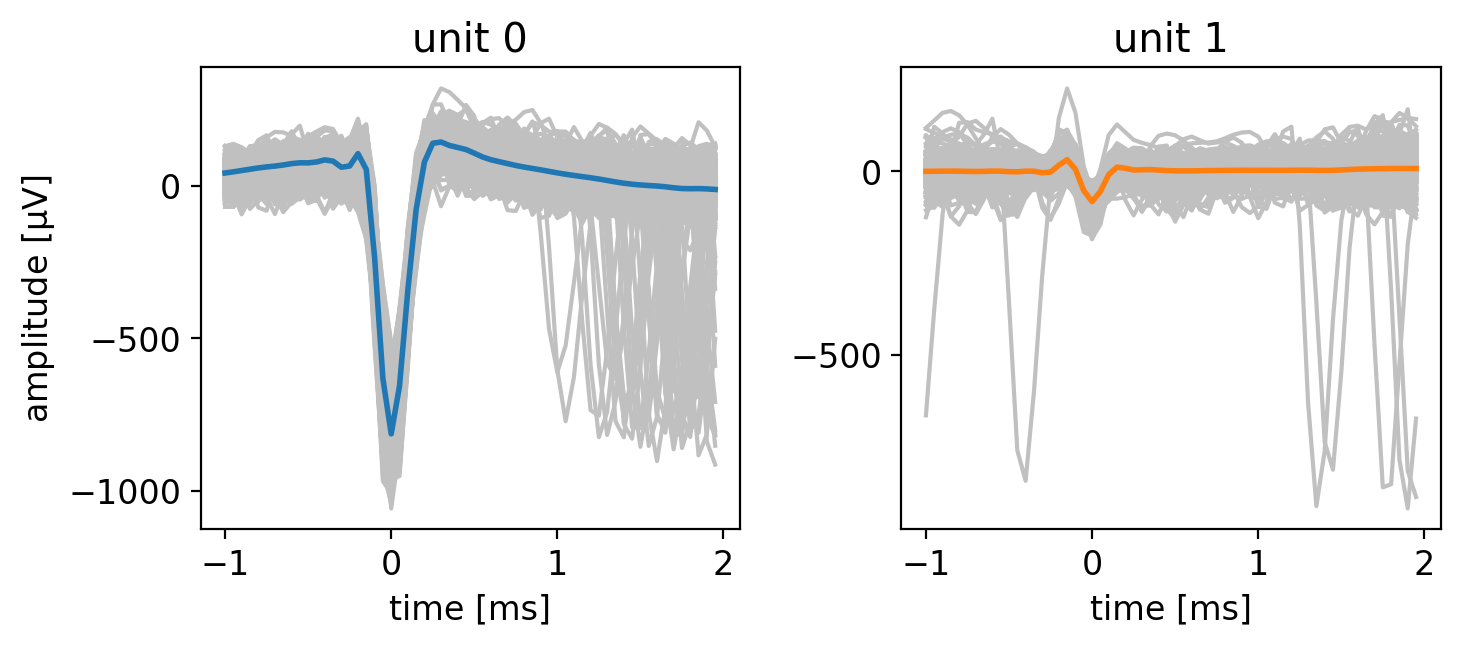
クラスタリング結果に基づき,各クラスタに属する波形,および加算平均波形をプロットした.クラスタリング結果が正しいと仮定した場合,加算平均波形は単一細胞の波形を忠実に表しているため,テンプレート (template)と呼ぶ.
Tip
unit 0は振幅が大きく,unit 1は振幅が小さい.振幅の小さなunit 1は,SN比が相対的に低いため,特徴空間上でばらつきが大きい.unit 0の信頼性はunit 1と比較して高いが,unit 1については電極から離れたいくつかの細胞の信号が分離しきれていない可能性もある.実践的には,振幅の大きなunit 0のみを抽出し,unit 1は解析対象から外す,といった判断を取ることも考えたい.
以上では,単一の電極の信号のみを用いてspike-sortingしたが,以下では隣接する9つの全電極を用いて同様の解析を行う.
peaks, waveforms = extract_waveforms(sig, peaks, n_pre, n_post)
waveforms_concat = concat_waveforms(waveforms)
print(waveforms.shape)
print(waveforms_concat.shape)
(2595, 9, 60)
(2595, 540)
pca = PCA(n_components=2, random_state=0)
pca.fit(waveforms_concat.T)
waveforms_pca = pca.components_.T
dc = DBSCAN(eps=0.01, min_samples=10).fit(waveforms_pca)
labels = dc.labels_
n_clusters = np.max(labels) + 1
plt.figure(figsize=(3, 3))
# units
for i in range(n_clusters):
idx = (labels == i)
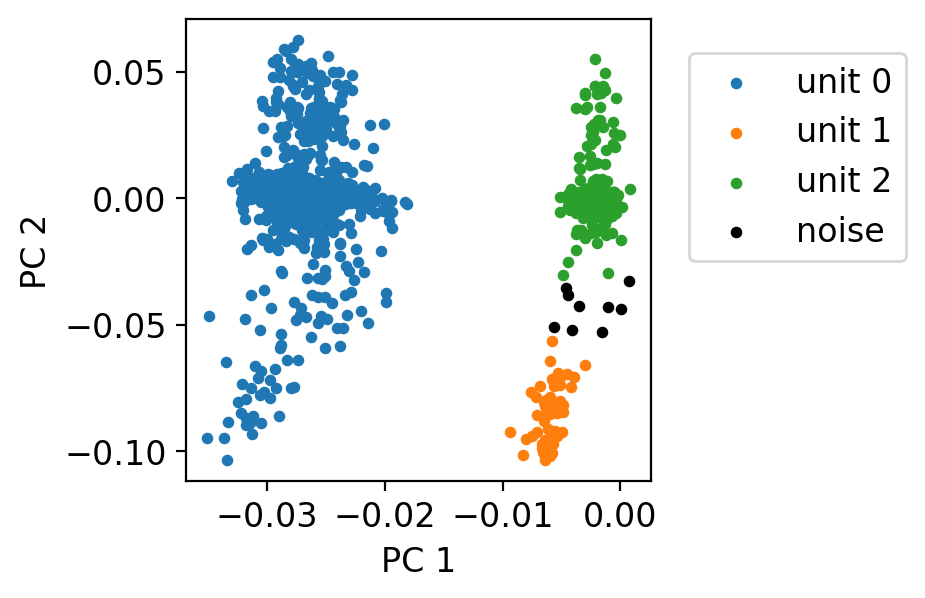
plt.scatter(x=waveforms_pca[:, 0][idx], y=waveforms_pca[:, 1][idx], s=10, label=f'unit {i}')
# outliers are labeled as -1
idx = (labels == -1)
plt.scatter(x=waveforms_pca[:, 0][idx], y=waveforms_pca[:, 1][idx], s=10, c='k', label='noise')
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(bbox_to_anchor=(1.01, 1), loc='upper left', borderaxespad=1, fontsize=12)
plt.show()
fig, axes = plt.subplots(n_clusters, 1, figsize=(10, 6))
for i in range(n_clusters):
ax = axes[i]
ax.set_ylim(-1000, 500)
ax.set_title(f'unit {i}')
idx = (labels == i)
for waveform in waveforms_concat[idx]:
ax.plot(waveform, c='#C0C0C0')
ax.plot(np.mean(waveforms_concat[idx], axis=0), linewidth=2.0, c=f'C{i}')
ymin, ymax = ax.get_ylim()
ax.vlines(np.arange(60, 9*60, 60), ymin=ymin, ymax=ymax, colors='k', linestyle='dashed', linewidth=1.0, alpha=0.8)
ax.set_axis_off()
plt.show()
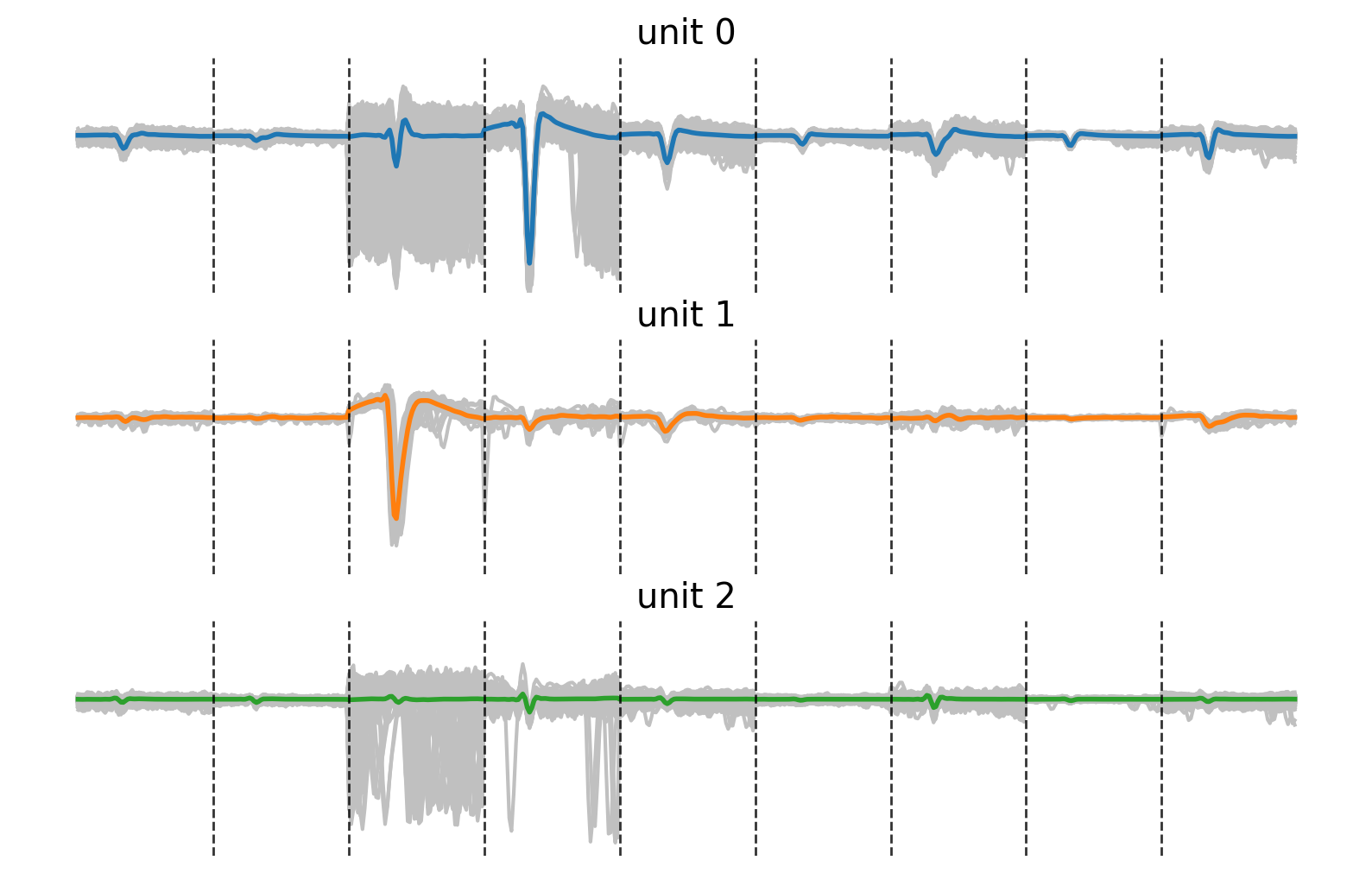
9つの電極における信号を横に連結した形でtemplateを表示した.各点線は電極の切り替わりを示す.先ほどのsortingでは左から4番目の電極を用いた.今回のsortingでは,先ほど同一のクラスタとして推定されたunit 1およびunit 2が分離できていることがわかる.
このように,単一電極におけるspike波形ではなく,複数の電極にまたがったspike波形の空間的な分布の違いを活用すると,sortingの精度が向上することが多い.
2.3. Template Matching#
上記のspike-sortingで抽出したテンプレートを用いて,spike検出をneuronごとにやり直す例を述べる.
この方法が有効なケースは,例えば次の通りである.長期にわたる計測で全データにおけるクラスタリングが困難な場合,一部の計測のみを用いてテンプレートを作成し,残りは計算量の少ないテンプレートマッチングでneuronのspike時刻を割り当てれば,同じneuronを長期にわたって追跡することが可能である.
まず,spike-sorting同様にspike検出を行い,波形を抽出する.その後,テンプレートと抽出された各波形のコサイン類似度を取り,類似度の閾値を決め,閾値以上の類似度を持つ波形を該当ニューロンに割り当てる.
from sklearn.metrics.pairwise import cosine_similarity
def extract_template(waveforms):
return np.mean(waveforms, axis=0)
# extract template for unit (unit_id)
unit_id = 0
template = extract_template(waveforms[labels == unit_id])
template_concat = template.flatten()
# calculate cosine similarity between the template and all the waveforms of peaks detected
dist = cosine_similarity(np.atleast_2d(template_concat), waveforms_concat).flatten()
plt.figure(figsize=(6, 2))
plt.title('histogram of cosine similarity values')
hist, edges, _ = plt.hist(dist, bins=np.linspace(0.0, 1.0, 100), color='#C0C0C0')
plt.xlabel('similarity')
plt.ylabel('count')
plt.show()
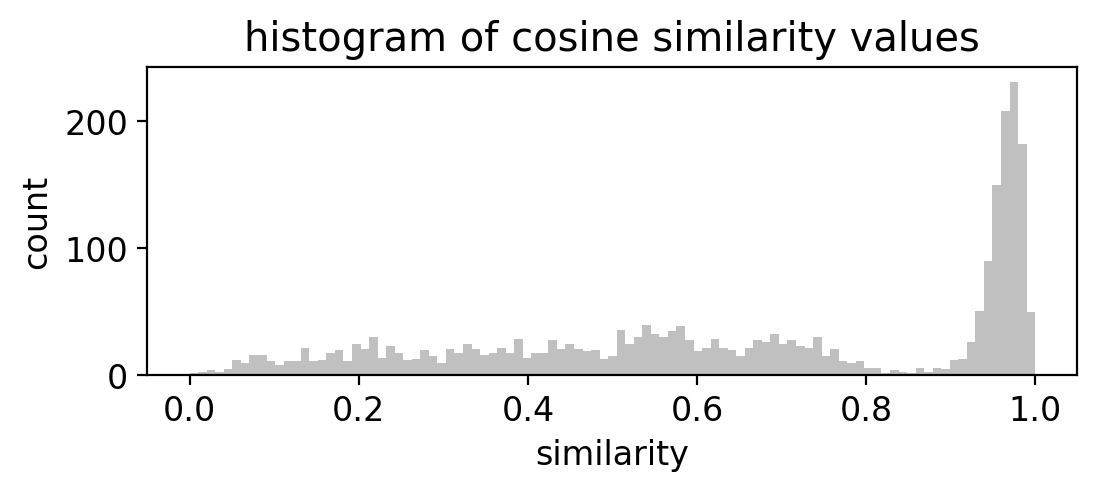
コサイン類似度のヒストグラムを取り,類似度が1.0に近い領域でピークが立っている場合,ピークに属する部分がtemplateと同一の細胞によるspikeであると考えられる.
ヒストグラムが与えられた際の閾値設計については,特に画像の2値化の文脈でさまざまな手法が提案されている.大津法やk-means, GMMなどクラスタリング手法を利用した手法,KL情報量最大化などの手法があるため,解析に応じて選ぶとよい.
次の記事が参考になる.
https://qiita.com/yuji0001/items/29c02b4fa1506edbdf19
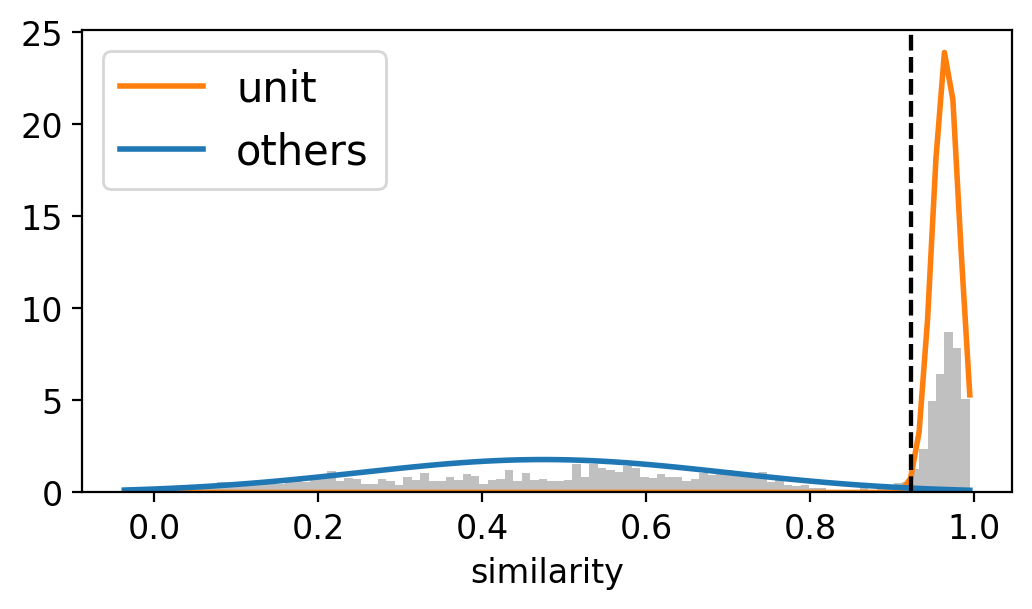
以下は,GMMを利用して2クラスタの境界を類似度の閾値とする例である.ヒストグラム(分布)は必ずしも2クラスタの正規分布に従うわけではないため,信頼性の高い推定を行うには境界が類似度0.8以上の場合のみ解析対象とする,などの判断が必要であろう.
# obtain the histogram of similarity values
plt.figure(figsize=(6, 3))
hist, edges, _ = plt.hist(dist, bins=100, density=True, color='#C0C0C0')
# decide threshold by GMM fitting
gm = GaussianMixture(n_components=2, random_state=0, covariance_type='full')
gm.fit(dist.reshape(-1, 1))
p = gm.predict(edges.reshape(-1, 1)) # class labels
thr = edges[np.where(p == gm.means_.argmax())[0].min()] # the boundary of two clusters
print(f'similarity threshold: {thr:.3}')
# order clusters by their mean in descending order
names = ['unit', 'others']
colors = ['C1', 'C0']
clusters = list(gm.means_[:, 0].argsort()[::-1])
for i in range(2):
j = clusters.index(i)
plt.plot(edges, stats.norm.pdf(edges, gm.means_[j][0], np.sqrt(gm.covariances_[j][0])), linewidth=2.0, label=names[i], c=colors[i])
plt.axvline(x=thr, c='k', linestyle='dashed')
plt.xlabel('similarity')
plt.legend(fontsize=15)
plt.show()
similarity threshold: 0.923
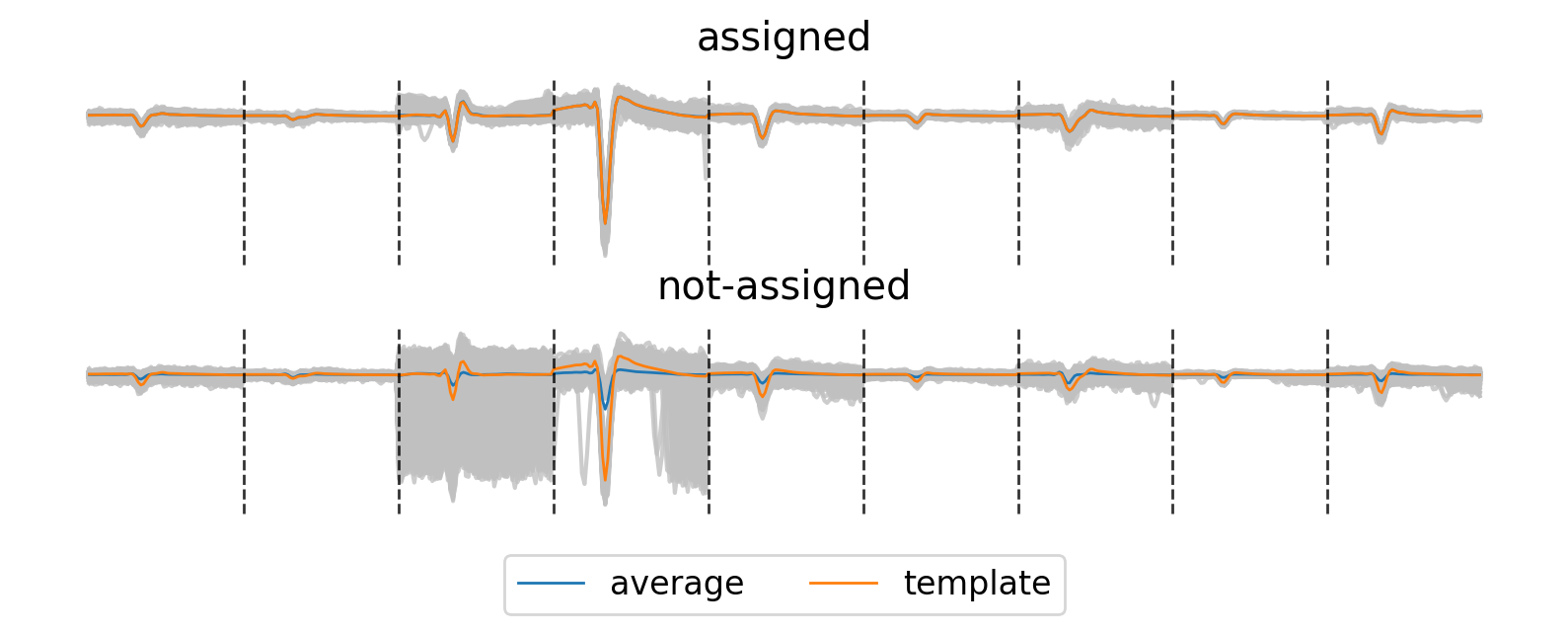
上のヒストグラムで決定された類似度の閾値をもとに,spike波形をテンプレートマッチングにより再割り当てした結果を次に示す.
assignedで示された波形群を加算平均した形状(青線)は,templateに一致する.一方で,not-assignedで示された波形群の加算平均はtemplateに一致しないものの,いくつかunit 0に属すると考えられるspike波形の取りこぼし(false-negative)があることもわかる.左から3番目の電極においてspike波形のばらつきが大きく,この電極の信号が類似度の低下に寄与していると考えられる.
実践的な対策としては,まずばらつきの小さなunit 1からspikeを割り当てていき,割り当て成功後は元の信号からマッチングされたtemplateを差し引いていくことで,spikeの重なり(overlap)を処理するという操作をはさむことが考えられる.
idx = (dist > thr)
fig, axes = plt.subplots(2, 1, figsize=(10, 3))
ax = axes[0]
ax.set_title('assigned')
for waveform in waveforms_concat[idx]:
ax.plot(waveform, color ='#C0C0C0', alpha=0.8)
ax.plot(np.mean(waveforms_concat[idx], axis=0), color='C0', linewidth=1.0, label='average')
ax.plot(template_concat, color='C1', linewidth=1.0, label='template')
ax = axes[1]
ax.set_title('not-assigned')
for waveform in waveforms_concat[np.logical_not(idx)]:
ax.plot(waveform, color ='#C0C0C0', alpha=0.8)
ax.plot(np.mean(waveforms_concat[np.logical_not(idx)], axis=0), color='C0', linewidth=1.0, label='average')
ax.plot(template_concat, color='C1', linewidth=1.0, label='template')
ax.legend(bbox_to_anchor=(0.5, -0.60), loc='lower center', borderaxespad=1, fontsize=12, ncols=2)
for ax in axes:
ymin, ymax = ax.get_ylim()
ax.vlines(np.arange(60, 9*60, 60), ymin=ymin, ymax=ymax, colors='k', linestyle='dashed', linewidth=1.0, alpha=0.8)
ax.set_axis_off()
plt.show()
2.4. Spike-Sorting Toolboxes#
spike-sortingの手法としてこれまでに数々の手法が提案されている.過程がブラックボックスになるというデメリットはあるものの,既存のツールボックスを使って解析を効率化するという手もある.
spike-sortingに関するレビュー論文としては,[RPQuianQuiroga15], [CC19], [BGY22]あたりが参考になる.
ツールボックスとして代表的なものは,EToS [TIF10],Kilosort [PSK+16], MountainSort [CMB+17],SPyKing-Circus [KYS+18],YASS [LMS+20]など.また,近年ではPythonから様々なspike-sorterを一貫したメソッドで呼び出し,sorter同士の結果を比較することができるSpike-Interface [BHG+20]もリリースされている.
MEA上でsortingされた各細胞の解析事例としては[HSP+17]が参考になる.
- BGY22
Alessio P Buccino, Samuel Garcia, and Pierre Yger. Spike sorting : new trends and challenges of the era of high-density probes. Progress in Biomedical Engineering, pages 0–15, 2022.
- BHG+20
Alessio P. Buccino, Cole L. Hurwitz, Samuel Garcia, Jeremy Magland, Joshua H. Siegle, Roger Hurwitz, and Matthias H. Hennig. Spikeinterface, a unified framework for spike sorting. eLife, 9:1–24, 2020. doi:10.7554/eLife.61834.
- CC19
David Carlson and Lawrence Carin. Continuing progress of spike sorting in the era of big data. apr 2019. doi:10.1016/j.conb.2019.02.007.
- CMB+17
Jason E. Chung, Jeremy F. Magland, Alex H. Barnett, Vanessa M. Tolosa, Angela C. Tooker, Kye Y. Lee, Kedar G. Shah, Sarah H. Felix, Loren M. Frank, and Leslie F. Greengard. A Fully Automated Approach to Spike Sorting. Neuron, 95(6):1381–1394.e6, sep 2017. doi:10.1016/j.neuron.2017.08.030.
- HSP+17
Gerrit Hilgen, Martino Sorbaro, Sahar Pirmoradian, Jens Oliver Muthmann, Ibolya Edit Kepiro, Simona Ullo, Cesar Juarez Ramirez, Albert Puente Encinas, Alessandro Maccione, Luca Berdondini, Vittorio Murino, Diego Sona, Francesca Cella Zanacchi, Evelyne Sernagor, and Matthias Helge Hennig. Unsupervised Spike Sorting for Large-Scale, High-Density Multielectrode Arrays. Cell Reports, 2017. doi:10.1016/j.celrep.2017.02.038.
- KYS+18
David Kleinfeld, Pierre Yger, Giulia LB Spampinato, Elric Esposito, Baptiste Lefebvre, Sté phane Deny, Christophe Gardella, Marcel Stimberg, Florian Jetter, Guenther Zeck, Serge Picaud, Jens Duebel, and Olivier Marre. A spike sorting toolbox for up to thousands of electrodes validated with ground truth recordings in vitro and in vivo. eLife, 2018. URL: https://doi.org/10.7554/eLife.34518.001, doi:10.7554/eLife.34518.001.
- LMS+20
Jin Hyung Lee, Catalin Mitelut, Hooshmand Shokri, Ian Kinsella, Nishchal Dethe, Shenghao Wu, Kevin Li, Eduardo Blancas Reyes, Denis Turcu, Eleanor Batty, Young Joon Kim, Nora Brackbill, Alexandra Kling, Georges Goetz, E. J. Chichilnisky, David Carlson, and Liam Paninski. YASS: Yet another spike sorter applied to large-scale multi-electrode array recordings in primate retina. bioRxiv, pages 1–46, 2020. doi:10.1101/2020.03.18.997924.
- MullerBL+15
Jan Müller, Marco Ballini, Paolo Livi, Yihui Chen, Milos Radivojevic, Amir Shadmani, Vijay Viswam, Ian L Jones, Michele Fiscella, Roland Diggelmann, and others. High-resolution cmos mea platform to study neurons at subcellular, cellular, and network levels. Lab on a Chip, 15(13):2767–2780, 2015.
- PSK+16
Marius Pachitariu, Nicholas A Steinmetz, Shabnam N Kadir, Matteo Carandini, and Kenneth D Harris. Fast and accurate spike sorting of high-channel count probes with kilosort. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016. URL: https://proceedings.neurips.cc/paper/2016/file/1145a30ff80745b56fb0cecf65305017-Paper.pdf.
- RPQuianQuiroga15
Hernan Gonzalo Rey, Carlos Pedreira, and Rodrigo Quian Quiroga. Past, present and future of spike sorting techniques. oct 2015. doi:10.1016/j.brainresbull.2015.04.007.
- TIF10
Takashi Takekawa, Yoshikazu Isomura, and Tomoki Fukai. Accurate spike sorting for multi-unit recordings. European Journal of Neuroscience, 31(2):263–272, 2010. doi:10.1111/j.1460-9568.2009.07068.x.